25. November 2020
Es wird angenommen, dass der vorherige Artikel schon gelesen wurde.
Teil einer Artikelserie:
Inhaltsverzeichnis:
1. Ein lokales git-Repository
Hierfür sucht man sich zunächst einen leeren Ordner (oder man erstellt einen). In diesem öffnet man ein Terminal.
Wenn man nun git init ausführt, dann hat man dort einen versteckten .git Ordner und somit ein git-Repository.
Das signalisiert auch die Ausgabe:
Leeres Git-Repository in /.../gittest/temp/.git/ initialisiertEin wirklich sehr nützliches Kommando ist git status. dann ist die Ausgabe
Auf Branch master
Noch keine Commits
nichts zu committen (erstellen/kopieren Sie Dateien und benutzen
Sie "git add" zum Versionieren)Commits und der master-Branch sollten schon bekannt sein. Das Konzept der Staging-Area und des Arbeitsverzeichnisses wurde aber noch nicht erklärt.
Um bequem mit git zu arbeiten braucht man die Daten nicht nur in einem CAS, sondern direkt in einem “normalen” Ordner. Dieser “normale” Ordner ist das Arbeitsverzeichnis - der Ordner, in dem man git init ausgeführt hat.
Um das Erstellen von Commits angenehmer zu machen, gibt es die Staging Area. Diese “sieht” man nicht direkt, aber man kann sie mittels git bearbeiten. In dieser speichert man die Veränderungen, die man im nächsten Commit speichern möchte. Die Ausgabe von git status hat schon gesagt, wie man Dateien zum Committen vorbereitet - mit git add [pfad].
Daher wird nun eine Datei erstellt mittels echo test > test. Dann kann man diese mittels git add test vormerken. Danach zeigt git status das auch an:
Auf Branch master
Noch keine Commits
Zum Commit vorgemerkte Änderungen:
(benutzen Sie "git rm --cached ..." zum Entfernen aus der Staging-Area)
neue Datei: test Dann wird es Zeit für einen Commit, aber davor muss man noch seine Personalien angeben, weil git sonst meckert. Diese “Personalien” werden im Commit gespeichert. Im lokalen Test-Projekt ist das egal, aber wenn man an einem öffentlichen Projekt mitwirkt, sollte man überlegen welche Daten man angibt.
git config --global user.name "Max Mustermann"
git config --global user.email max.mustermann@anoxinon.mediaDie Daten werden mit diesen Befehlen global festgelegt, sie gelten also in allen git-Repositories, wenn man dort neue Commits erstellt. Wenn man --global weglässt, dann gelten die Einstellungen nur für das
git-Repository, in dem man den Befehl ausgeführt hat.
Mittels git commit kann man einen Commit erstellen. Hierfür wird ein Editor geöffnet, in dem man seine Commit-Message (Notiz, was man geändert hat) eingibt. Danach speichert man und schließt den Editor. Damit erstellt git einen Commit - sofern man eine Commit Message hinterlegt hat, sonst wird abgebrochen.
Wie man den Editor auswählt, steht in der git-Dokumentation. Je nach System kann vi(m) der Standardeditor sein, was für Anfänger irritierend sein kann.
Die erste Zeile der Commit-Beschreibung sollte eine kurze Zusammenfassung sein. Wenn man noch etwas Genaueres schreiben will, lässt man eine Zeile frei und schreibt danach eine längere Beschreibung. Diese Konvention ist sinnvoll, da die meisten Oberflächen in Commitlisten nur die erste Zeile anzeigen und man bei Bedarf alles anzeigen kann.
Den Commit kann man sehen - per git log:
commit c35487dc517e306e075949e184a566995adf04d5 (HEAD -> master)
Author: Max Mustermann
Date: Mon Jan 6 12:00:00 2020 +0100
My first commit Jetzt kann man Dateien ändern, erstellen und committen …
Einige Anmerkungen noch:
- mittels
git rmkann man Dateien löschen - mittels
git commit -akann man alle Änderungen committen, ohne diese zur Staging Area hinzuzufügen - mittels
git diffkann man die Änderungen sehen, die noch nicht in der Staging Area sind - mittels
git diff --cachedkann man die Änderungen sehen, die in der Staging Area sind - mittels
git reset --hard HEADkann man den Zustand vom letzten Commit wiederherstellen
2. Branches
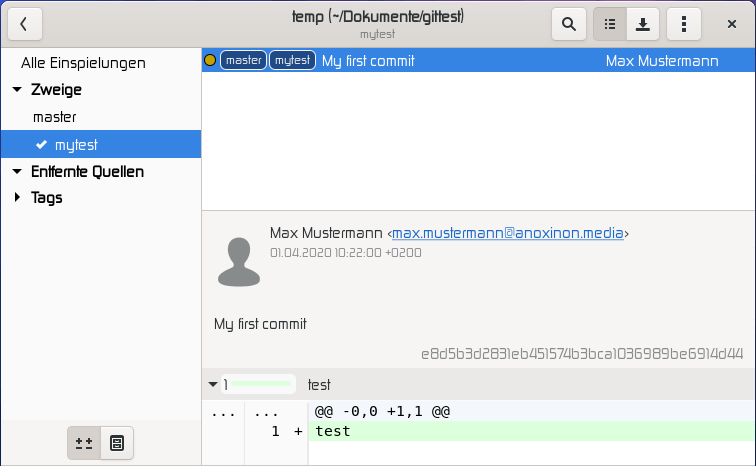
Das Erstellen eines Branches ist einfach - git branch mytest erstellt einen Branch mit dem Namen mytest. Dieser hat den momentan sichtbaren Commit als Anfangszustand. Allerdings verrät git status, dass man immer noch auf dem Branch master ist. Das Wechseln erfolgt mittels git checkout mytest. Nun kann man Branches wechseln und Commits erstellen.
Zur Visualisierung hier die Darstellung in gitg,
einer freien grafischen Oberfläche für git unter Linux.
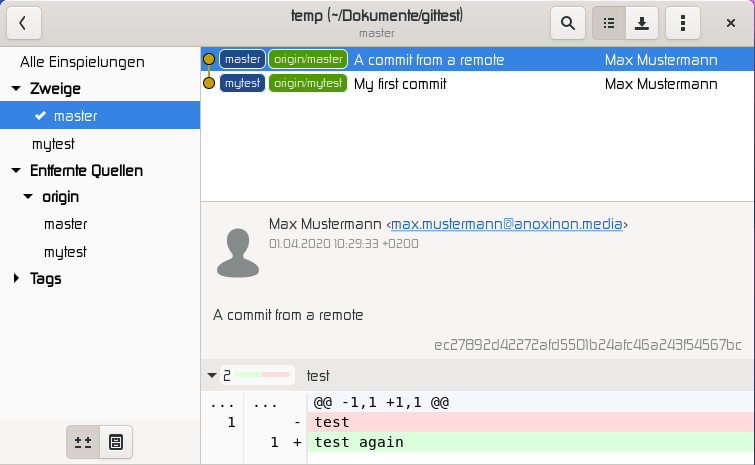
Es fehlt noch das Mergen, also das Importieren von Änderungen aus einem Branch. Nun sei angenommen, dass im Branch mytest ein Commit erstellt wurde und wieder zum Master-Branch gewechselt wurde. Dann kann man git merge mytest ausführen. Wenn man danach git log betrachtet sieht man die neuen Commits.
Man kann auch in die andere Richtung mergen. Wenn es beispielsweise eine neue Funktion im master-Branch gibt, dann kann man den master-Branch in den Arbeitsbranch mergen. Somit hat man einerseits die neue Funktion und andererseits vermeidet man Probleme (Merge-Konflikte) beim Zurückmergen in den master.
Mergekonflikte machen Spaß … git informiert in so einem Fall. Man ruft git status auf, um die entsprechenden Dateien anzuzeigen und die Konflikte zu beheben. Danach kann man das Mergen mittels git commit -a abschließen.
3. Server
Hier wird nicht mit einem echten Server gearbeitet, sondern mit einem weiteren git-Repository. Da es als Server dienen soll wird es ein sogenanntes Bare-Repository. Dieses ist nicht zum direkten Arbeiten gedacht und hat daher weder eine Staging Area noch ein Working Directory. Es ähnelt dem .git-Ordner eines normalen git-Repositories.
Man nimmt einen anderen leeren Ordner und führt dort git init --bare . aus.
Zurück im ersten Repository kann man diesen Server hinzufügen - mittels git remote add origin /.../gittest/temp2. origin ist hierbei nur ein Name - man könnte auch irgendetwas anderes dort hinschreiben. Mittels git remote -v kann man sich die Serverliste anzeigen lassen:
origin /.../gittest/temp2/ (fetch)
origin /.../gittest/temp2/ (push)Um etwas an den Server zu senden führt man git push aus. Aber das klappt noch nicht:
fatal: Der aktuelle Branch master hat keinen Upstream-Branch.
Um den aktuellen Branch zu versenden und den Remote-Branch
als Upstream-Branch zu setzen, benutzen Sie
git push --set-upstream origin masterDie Lösung steht schon da. Damit gibt man an, dass man jetzt und zukünftig den origin als Standardpushziel verwenden möchte. Gleichzeitig legt man damit die Standardquelle für das Abrufen mittels git pull fest.
Damit wurde jetzt nur der Master-Branch gesendet. Diese Prozedur muss man für jeden Branch wiederholen, den man auf dem Server haben möchte.
Allerdings möchte man oft ein git-Repository benutzen, dass es schon gibt. Dafür gibt es auch eine Lösung. Erstmal braucht man wieder einen Ordner, der nicht in einem der bestehenden git-Repositories liegt. Der Zielordner muss nicht leer sein, weil automatisch ein neuer Ordner erstellt wird. Allerdings darf dort noch kein Ordner sein, der so heißt wie das zu holende git-Repository.
Nun wird das Bare-Repository geklont - mittels git clone /.../gittest/temp2. Anstelle des Pfades hätte man auch eine Server-URL angeben können.
In dieser Kopie kann man nun einen Commit erstellen. Anschließend kann man ihn mittels git push an den Server senden. Wenn man im Original-Repository git pull ausführt, dann hat man die Änderungen auch dort.
4. digitale Signaturen
Seine Commits kann man per PGP signieren. Das setzt voraus, dass man schon einen Schlüssel hat und dieser lokal oder auf einer verbundenen Smartcard vorliegt.
Hierfür ist es zielführend, git zu sagen, welchen Schlüssel man verwenden möchte
- mittels git config --global user.signingkey KeyId.
Wenn man etwas signieren möchte, dann verwendet man den Parameter -s, also z.B. git commit -s.
Wenn man immer signieren will und es nicht jedesmal angeben will, kann man auch git config --global commit.gpgsign true ausführen.