29. September 2020
Git ist eine Versionsverwaltung. Als Außenstehender wird man wahrscheinlich denken, dass man so etwas nicht braucht. Aber spätestens wenn man an einem Projekt mitwirken möchte, bei dem git eingesetzt wird, ändert sich das.
Teil einer Artikelserie:
Inhaltsverzeichnis:
Commits
1.1 5abdba ist auch eine Version
1.2 Inhalte eines Commits
1.3 Versionen ohne Versionsverwaltung
1.4 Commits bilden den Verlauf
1.5 Commits alleine sind unübersichtlichBranches
2.1 Arbeiten in Branches
2.2 Organisation mit Branches
2.3 Forks
1. Commits
1.1 5abdba ist auch eine Version
Es ist zunächst sinnvoll zu klären, was in diesem Kontext eine Version ist.
Wer bei Version an Version 1.2.3 denkt, der irrt sich hier. Bei git
sieht eine Version eher so aus wie 5adba5de66ee39d41784928b14b1fd3c24fc0909.
Dort ist eine Version nicht nur etwas, das veröffentlicht/verwendet wird,
sondern auch ein Zwischenstand zwischen zwei Veröffentlichungen. Es heißt auch
nicht direkt “Version”, sondern “Commit”.
1.2 Inhalte eines Commits
Ein Commit umfasst eine Beschreibung, den Autor, den Zeitpunkt, die eigentlichen Daten und den/die vorherigen Commits (in der Regel gibt es einen vorherigen Commit, aber der erste Commit hat keinen Vorgänger und bei sog. Merge-Commits hat man mindestens zwei Vorgänger). Um etwas in git zu speichern, erstellt man immer einen Commit. Die “eigentlichen Daten” sind Dateien, die man evtl. in einer Ordnerstruktur organisiert hat.
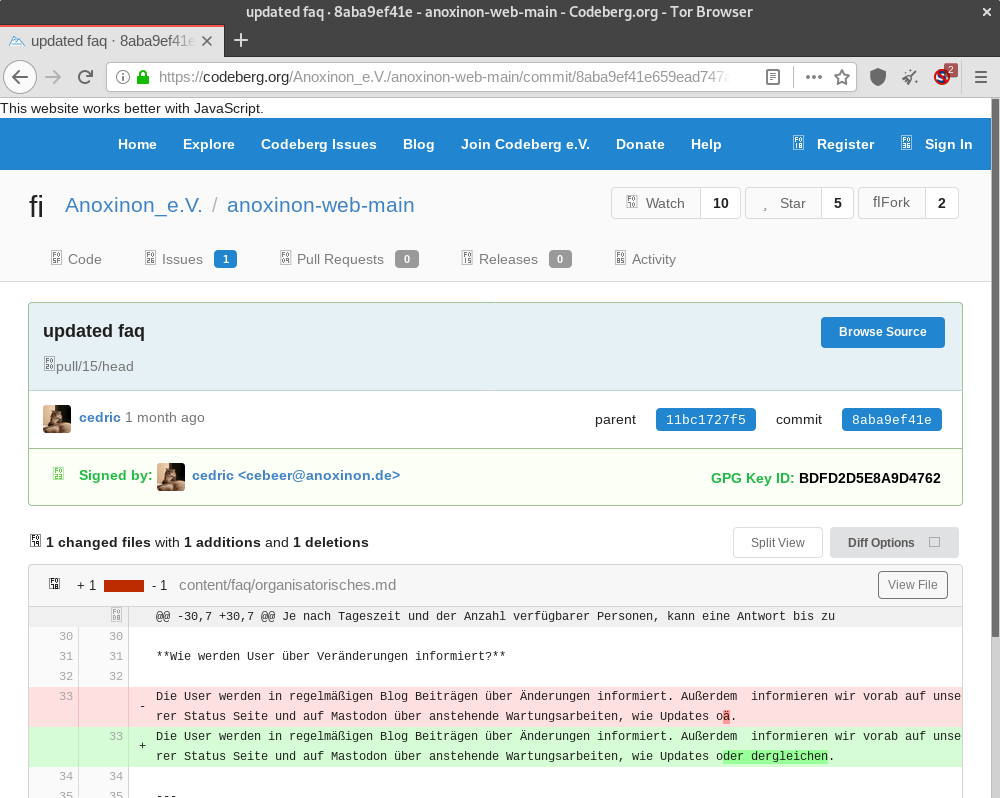
Das Bild zeigt hier einen Commit bei der Webseite anoxinon.de. Weil es in der Regel besonders interessant ist, was sich geändert hat, wird hier gleich die Änderung angezeigt.
1.3 Versionen ohne Versionsverwaltung
Ohne git bzw. ohne Versionsverwaltung würde man ein Changelog erstellen oder fortsetzen, eine Kopie vom Projektordner in ein tar- oder zip-Archiv packen und diese Archivdatei archivieren.
Nun ist git, als dafür spezialisiertes Werkzeug, besser als das Arbeiten mit vielen archivierten Projektversionen.
Git speichert die Daten in dem versteckten Unterordner .git in einem Projekt.
Dabei verwendet git einen Content Addressed Storage (CAS),
was dazu führt, dass gleiche/unveränderte Dateien nicht mehrmals gespeichert werden (wie es bei dem Ansatz mit
den Archivdateien wäre), wodurch man viele Versionen mit wenig Speicherplatzbedarf speichern kann.
Das ist bei kleineren Projekten egal, aber spätestens beim Linux-Kernel, für dessen Entwicklung git entwickelt wurde,
wird es relevant.
1.4 Commits bilden den Verlauf
Vorhin wurde erwähnt, dass ein Commit auch den vorherigen Commit umfasst. Und dieser vorherige Commit umfasst dessen vorherigen Commit. Schlussfolgerung? Wenn man einen Commit hat, hat man auch alle vorherigen. Wenn man also einen Fehler macht oder einfach nur nachsehen möchte, wann wer wie was verändert hat, dann kann man das anhand der Commits nachvollziehen.
1.5 Commits alleine sind unübersichtlich
Nun hat man einen Haufen Commits (oder in der Analogie Archivdateien). Diese muss man nun irgendwie organisieren. Deswegen gibt es Branches und Tags.
2. Branches
Ein Branch ist nichts Anderes als ein angenehmerer Name für einen Commit.
2.1 Arbeiten in Branches
Nun kann man bei git “in Branches arbeiten”. Dahinter verbirgt sich ein Trick. Der wird nur angewendet, wenn man einen Branch ausgewählt hat und einen neuen Commit erstellt. Falls man keinen Branch ausgewählt hat, gibt es beim Commiten von git eine Warnung zu einem “detached head” - und das nicht ohne Grund, weil man sonst seine neuen Commits verliert, sobald man wieder einen Branch auswählt. Die lassen sich zwar noch per git reflog wiederherstellen, aber es ist besser, wenn man das nicht braucht. Wie auch sonst wird der aktuelle Commit, auf den dann auch der Branch verweist, als Vorgänger für den neuen Commit verwendet. Zusätzlich wird der Branch so verändert, dass er danach auf den neuen Commit verweist. Damit wird der Verlauf vom Branch scheinbar um den neuen Commit erweitert.
2.2 Organisation mit Branches
Bei dem Erstellen eines neuen Projekts legt git den master-Branch (ein Branch mit dem Namen “master”) an. Nun gibt es verschiedene Organisationsstile in git, aber ein direktes Arbeiten im Hauptbranch ist eher unüblich. Stattdessen werden für bestimmte Zwecke neue Branches angelegt. Diese neuen Branches nutzen oft einen bestehenden Commit als Grundlage und arbeiten von diesem aus weiter. Später kann man dann Branches mergen, d.h. die Commits aus einem Branch werden in einen anderen übernommen. So kann man z.B. eine neue Funktion in einem Branch entwickeln und wenn ein anderer Entwickler die neue Funktion geprüft hat, kann er diese in den Master-Branch übernehmen.
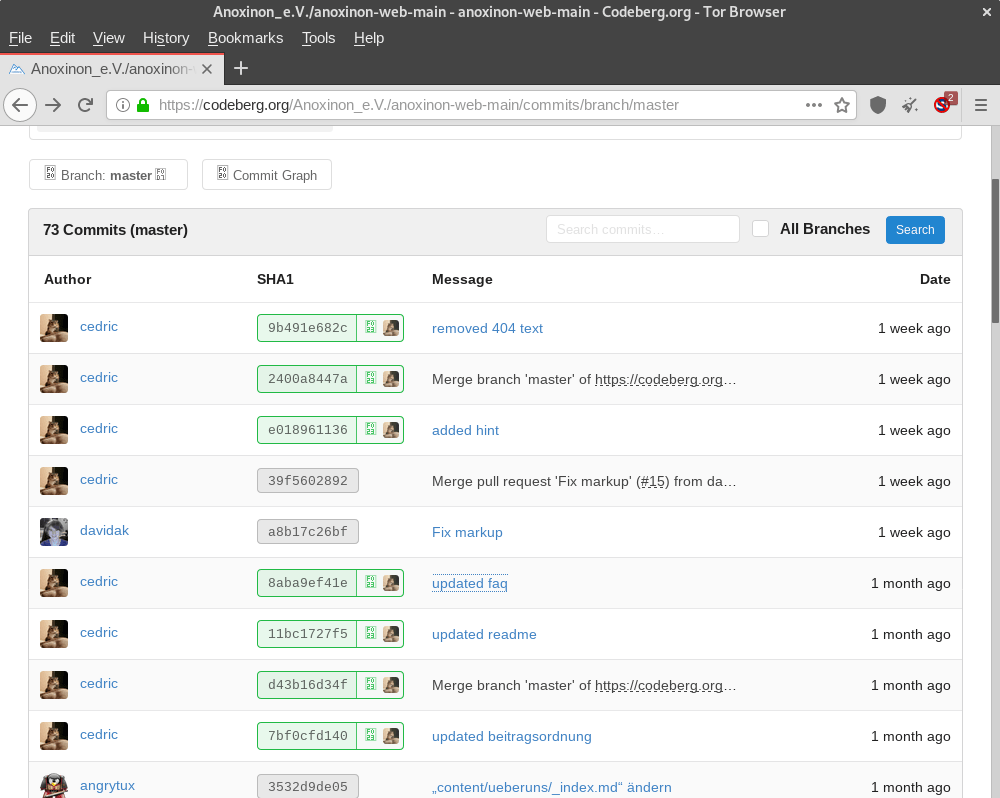
Das Bild zeigt den Master-Branch der Webseite anoxinon.de. Oben ist der neuste Commit, darauf folgen die vorherigen Commits.
2.3 Forks
Je nach Organisation können auch sogenannte Forks im Rahmen der Entwicklung eingesetzt werden. Diese werden insbesondere für Mitwirkende genutzt, die einmalig/das erste mal im Projekt mitarbeiten. Hierfür wird eine komplette Kopie eines git-Repositories erstellt, in der die Anpassungen vorgenommen werden. Anschließend wird das Projekt (der Upstream) kontaktiert und es wird um eine Übernahme der Änderungen gebeten, z.B. über eine Merge-Request-Funktion des Git-Hosting-Dienstes oder über das Einsenden einer sogenannten Patchfile, die git erstellen kann, die die Änderungen enthält. Diese Arbeit in einer vollständigen Kopie ähnelt der Arbeit in einem eigenen Branch, aber hat den Vorteil, dass man keine Schreibrechte auf das eigentliche Projekt haben muss. Daher wird diese Variante, obwohl sie etwas aufwändiger ist, verwendet.
3. Tags
Nun kommen noch die Tags. Angenommen, man will eine Version “1.2.3” nennen. Dann braucht man einen Tag. Ein Tag ist auch nur ein zusätzlicher Name für einen Commit, wobei ein Tag zusätzlich einen Text oder Versionshinweise wie z.B. ein Changelog speichern kann. Obowhl man Tags nach dem Erstellen auch noch verändern kann bzw. auf einen anderen Commit verweisen lassen kann, sollte man das vermeiden. Ansonsten kann es passieren, dass mehrere Nutzer die Version “1.2.3” verwenden und dann glauben, das gleiche zu verwenden, obowhl es verschiedene Versionen “1.2.3” nacheinander gab.
4. (Un)veränderbarkeit der Vergangenheit
Ein Tag und einen Branch kann man im Nachhinein verändern, indem man Sie auf einen anderen Commit zeigen lässt. Einen Commit kann man aber nicht mehr verändern. Ein Commit-Name sieht zufällig aus, aber er ist es nicht. Stattdessen ist es eine SHA1-Prüfsumme über alle Daten, die im Commit enthalten sind. Wenn man also die Inhalte eines Commits verändert und man nicht eine riesige Menge an Rechenleistung zur Verfügung hat, um ihn so zu verändern, dass die neue Prüfsumme mit der alten übereinstimmt, dann hat der Commit danach eine andere Prüfsumme. Da alle Verweise auf Commits die Prüfsumme nutzen, kann man dann ein git-Repository zerstören, aber die bestehenden Commits kann man nicht mehr verändern, ohne ihre Namen zu ändern. Da jeder Commit auf den vorherigen verweist, kann man nichts in der Vergangenheit umschreiben, ohne alle nachfolgenden Commits umzuschreiben. Wenn man nun etwas umschreibt, dann nimmt das erst einmal Niemand wahr. Wenn man auf einen Git-Server eine rückwirkend veränderte Historie speichern will, dann wird er das wahrnehmen, sodass man die Übernahme der Änderung erzwingen muss - aber das kann man als Projektleiter üblicherweise tun. Es fällt allerdings beim Abrufen durch die Benutzer auf. Wenn man ein Projekt heruntergeladen hat, dann kann man sich die seit dem letzten Abrufen durchgeführten Änderungen von git herunterladen lassen. Wenn der Commit, der beim vorherigen Abrufen der neuste war, bei dem neuen Zustand nicht als direkter oder indirekter Vorgänger auftaucht, dann gibt es nur eine Fehlermeldung. Kurzgefasst: Die Historie bei git ist veränderbar, aber bei Projekten, die nicht winzig sind, fällt es auf.
5. Arbeiten mit Servern
Jetzt war die Rede vom Server, ohne das genauer zu erklären. Bei Projekten mit mehreren Mitwirkenden oder Projekten, die etwas in Quelltextform veröffentlichen, ist ein gemeinsamer/öffentlicher Stand sinnvoll. Deswegen kann man git-Repositories auch auf Servern ablegen. Dann lädt man/der git Client gemäß den Nutzeranweisungen sich Branches, Tags und Commits herunter, sodass man lokal (und auch offline) arbeiten kann. Lokal macht man dann seine Änderungen wie es auch sonst passieren würde. Anschließend kann man - Schreibrechte vorausgesetzt - seine Änderungen an den Server senden, der diese dann speichert und anderen zur Verfügung stellt. Weil es git ist, gibt es mehrere mögliche Protokolle zur Kommunikation mit dem Server. Beispielsweise kann man als “Server” einen Ordner angeben, in dem die Daten gespeichert werden sollen, und dieser Ordner kann auch auf dem eigenen Rechner liegen. Man kann in git mehrere Server angeben. In den meisten Fällen hinterlegt man einen oder zwei Server: Wenn man ein Projekt nur nutzt oder wenn man dort Schreibrechte hat und dort mitwirkt, hinterlegt man genau diesen einen Server. Dafür verwendet man in der Regel den Servernamen “origin”. Wenn man in einem Fork arbeitet, dann nennt man den Server des Projekts in der Regel “upstream” und den eigenen Fork “origin”. Auch bei Servern wird in git mit Namen gearbeitet, damit man nicht bei jeder Aktion die gesamte Adresse mit dem Protokoll angeben muss. Es gibt sicherlich auch noch kompliziertere Szenarien, bei denen man mehr als zwei Server angibt, aber das sollte eher selten sein.
5.1 Protokolle
Die in der Praxis relevanten Protokolle sind HTTP(S) und SSH. Wenn man keine Schreibrechte hat verwendet man HTTP(S). Wenn man nur HTTP verwendet, dann könnte ein MITM (man in the middle) einem einen falschen Quelltext übermitteln, sodass man das aus Sicherheitsgründen vermeiden sollte, wenn man keine weiteren Verifikationen durchführt. Wenn man Schreibrechte hat kann man in der Regel HTTPS und SSH verwenden. Bei HTTPS muss man dann seine Zugangsdaten jedes Mal eingeben oder lokal speichern. Da bietet SSH mit zertifikatsbasierter Authentifizierung einen Vorteil - hier meldet man einmal seinen Rechner beim Git-Server an und dann kann man git nutzen, ohne sich jedes mal anzumelden, aber auch ohne eine direkte Speicherung der Zugangsdaten.
6. Ausblick
So weit zur Theorie - der Anwendung widmen wir uns in diesem Beitrag.
7. Quellen und Literatur
- https://git-scm.com/book/en/v2
- Kapitel 1.2 “Getting Started - A Short History of Git”
- Kapitel 1.3 “Getting Started - What is Git?”
- Kapitel 2.1 “Git Basics - Getting a Git Repository”
- Kapitel 2.2 “Git Basics - Recording Changes to the Repository”
- Kapitel 2.5 “Git Basics - Working with Remotes”
- Kapitel 2.6 “Git Basics - Tagging”
- Kapitel 4.1 “Git on the Server - The Protocols”
- Kapitel 5.1 “Distributed Git - Distributed Workflows”
- Kapitel 5.3 “Distributed Git - Maintaining a Project”
- Kapitel 10 “Git Internals”
- https://git-scm.com/docs/git-commit
- https://git-scm.com/docs/git-merge
- https://guides.github.com/activities/forking/
- https://githubflow.github.io/
- https://www.atlassian.com/git/tutorials/comparing-workflows/forking-workflow
- https://www.atlassian.com/git/tutorials/comparing-workflows/feature-branch-workflow
- https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow